
Using speech to text to find game SFX files
Saturday, April 4 2020 · Lesezeit: 7 Minuten · 1294 Wörter Achtung! Dieser Artikel ist älter als ein Jahr. Der Inhalt ist möglicherweise nicht mehr aktuell!I bought Red Dead Redemption 2 a few weeks ago and got addicted to the Blackjack minigame. I’ve never played Blackjack before but it is an interesting game. Out of boredome and as a proof of concept I’ve developed a simple CLI version of it one evening. On the second evening I added computer controlled players, doubling and splitting. Then I decided I wanted to move the frontend to the browser so I could play with my friends. I’ve very little experience with webdev but played with vue.js and bootstrap before. I know that websockets exist but never used it. So the foundation was there so I began developing and fighting with Javascript. Then there was a point in time where I added sound files for dealt or flipped cards I found online. But I wanted use the same sound files as Red Dead Redemption 2. In there are two types: Player and dealer sounds. The players say something like “I’ll stand”, “card please”, “hit me”. etc. The dealer says “That’s 17”, “17”, etc. In my head it should not be that complicated to find the sound files for that. My naive approach was to just explore the game files hoping to find raw audio files named something like “17.wav”. Of course that’s not the case. The audio files are stored in archives. And here is my journey to find them:
The tool I used to extract and SFX files is called OpenIV (🖇️ 🔐) . And honestly I thought it’d infect my PC with corona after downloading the application from some russian site. But to my surprise nothing bad happened and I was able to quickly find an archive containing the SFX files:
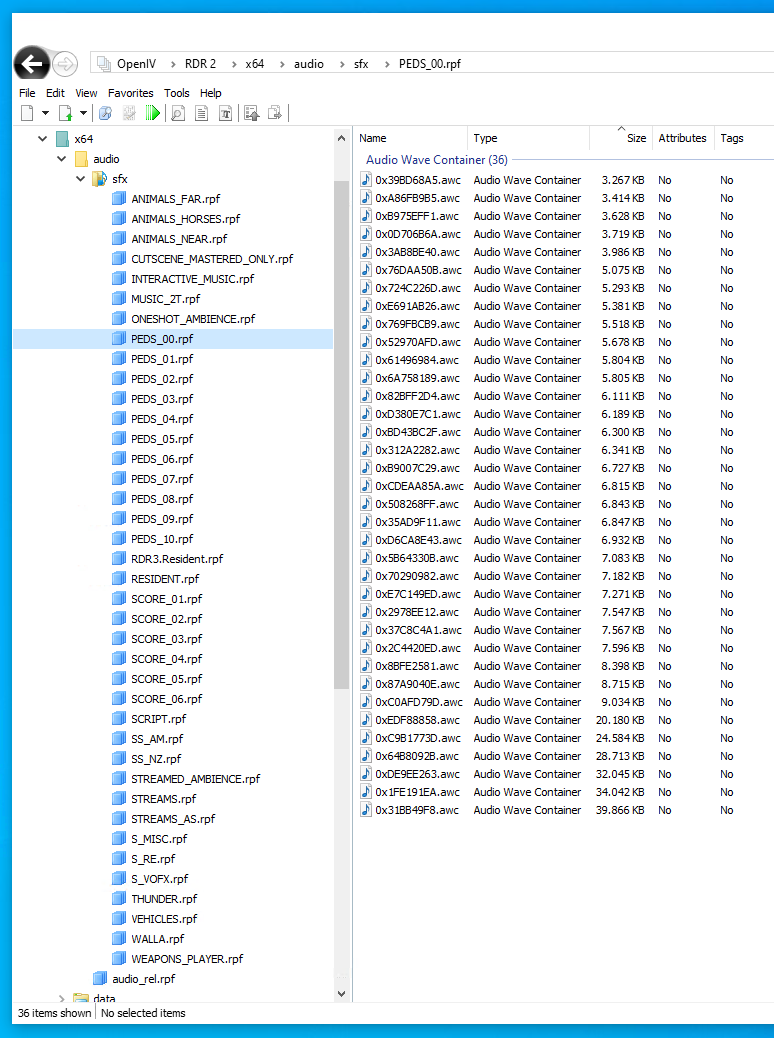
On the left side you can see groups. Each group contains multiple so called Audio Wave Container (AWC) entries. Each container itself contains multiple normal WAV files. If you double click on an AWC container a player windo opens and you can play each file in there.
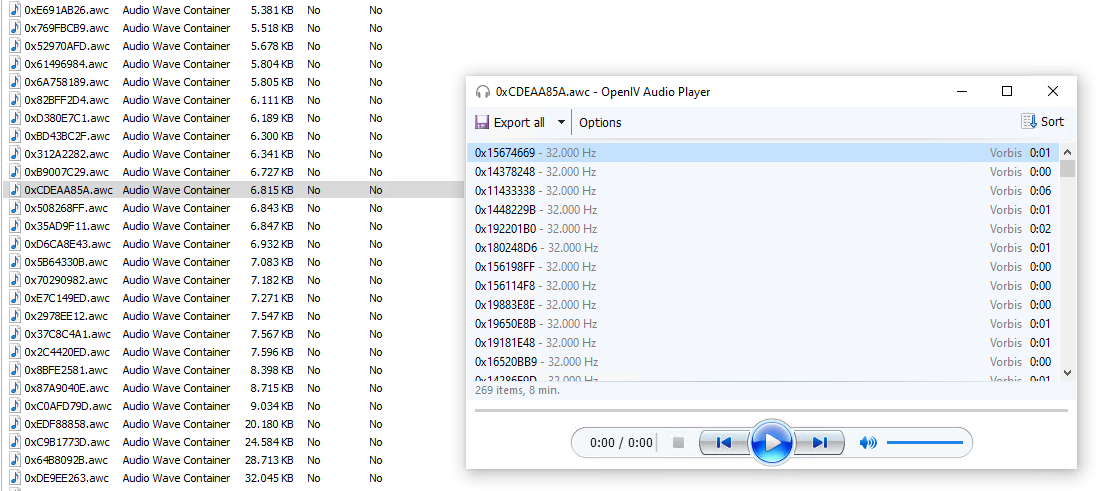
Here is the problem: The entries and file names are not human readable. So my wanted files are in there somewhere, but listening to every group/container/file is not possible. I’ve wasted 6 hours one evening to find some logical structure by clicking through every container and listening to the sounds. No success.
I found containers containing Johns and Arthurs general sounds like “Good day”, “Nice horse you got there”, “This is a robbery” etc. That was easy since they are the two main characters their AWC containers file sizes are pretty high. I’ve found everything except the dealer sounds I wanted so badly.
Today at 2 o’Clock I gave up and went to bed angry. This morning I got up and thought about a solution to this problem. I’ve not found a mapping file anywhere in the game files. And what do you do when you can’t find a solution on your own: You throw money at the problem. I wanted to use Googles speech to text service (🖇️ 🔐) to get a searchable text file mapping words and sentences to a sound file.
Extracting the SFX files
First of all I needed the raw sound files. They are stored in the WAV format and you can extract them easily with the OpenIV application. My best guess was that the sounds I wanted must be somewhere in the PEDS_* group. I think PEDS stands for pedestrians. So I’ve extracted each AWC container in each group into the file system. The result: 217662 files taking round about 30 GByte space.
Now I was able to listen to them with VLC without any problem. The cool thing about raw data is that they are clean recordings in studio quality. After my first try finding them manually I wanted to record couple of Blackjack rounds and cut out the parts I wanted from it. However there is a constant background noise. For example the piano player. You can scare him way, but the laughs from the other guests etc are still present. Very frustrating.
Googles Speech to Text
You can try their service out on the product page. I’ve uploaded round about 20 sounds and it had a 100% hit rate! No matter what topic or complexity. The text was 100% correct. Amazed by that result I scrolld down to check what Google would charge me for my file: 0,004 $ every 15 seconds. Files shorter are rounded up to the full 15 seconds. My files are all below 15 seconds. So each file would cost me 0,004 $. The math now is easy: 217662 files * 0,004 $ = 870,65 $. And then there is still a good chance that my wanted files are not in there. Damn!
Side note: Uploading the files to Google is probably probibited, because I don’t own the copyright.
Mozilla DeepSpeech
Mozilla is also a player on that market and has an Open Source solution based on TensorFlow (ironically a Google thing). In my Windows PC I’ve an AMD Ryzen 5 1600X processor with 6 cores and 12 threads. Since all the extracted sound files are already on there I tried out the Windows Subsystem for Linux. I installed an Ubuntu container (?) on it and installed deepspeech via pip in there. The windows C drive is mounted on /mnt so accessing the WAV files is easy. The pretrained ML files for english is already provided by Mozilla. So you don’t have to train on your own.
Next step was to write a script looping over the files and feed the audio files one by one to deepspeech and store the result:
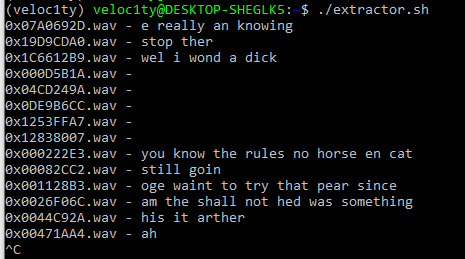
The result was not bad. Of course there are few errors. For example “you know the rules no horse en cat” should be “you know the rules no horses in camp” but for the beginning not bad. Remember: This is a pre-trained set and free.
Processing all files this way would’ve taken weeks. So I’ve developed a quick and dirty application in go to multithread the execution of deepspeech. You can find the source code here (🖇️ 🔐)
. With that and 20 “threads” my computer processed 100 sound files in 53 seconds using 100% of the CPU power. Doing the math again:
53 seconds / 100 files = 0,53 seconds per file
217662 files * 0,53 seconds/file = 115360,86 seconds = 1922,68 minutes = 32,04 hours
Let’s say 33 hours. Not bad! I left it running for an hour and went out getting groceriess. After I came back I paused the application and checked the so far collected results. I’ve searched through the text file for numbers, sentences etc but was not able to find anything. I left it running for another couple of hours but still no result. I then gave up.
Conclusion
Google has the perfect service for my needs, but copyright laws and the high cost prevent me from using it. It’s very scary what they build and/or trained there.
The open source software deepspeech from Mozilla is pretty nice and got okay results. Sadly I was not able to get usefull stuff out of it with the provided trained material. Training it myself is also not an option. I’ve no experience with machine learning and I don’t have the time to do it.
There are other services. I’ve found something backed by IBM Watson (🖇️ 🔐) . They use a websocket connection to transmit files and receive the result as JSON. Maybe I can piggy back that :-)
All I know is that they must be in there somewhere. Next step I want to try out and research is if I can match a recording with background noise and compare it to the raw sounds. Maybe there is a software testing for similarities.
Du hast einen Kommentar, einen Wunsch oder eine Verbesserung? Schreib mir doch eine E-Mail! Die Infos dazu stehen hier.
🖇️ = Link zu anderer Webseite
🔐 = Webseite nutzt HTTPS (verschlüsselter Transportweg) Zurück